
How do you make “Agile” more, well, agile?
Simple:
You allow the data to lead the way.
25 years ago, this was not even a pipedream (except, perhaps, for prescient, rockstar developers who are always looking ahead). 25 years ago, we had waterfall development, changes occurring in months and even years, and private, walled-off IP.
Today, we’re right on the precipice of a reality that’s more agile than Agile — as we move from Agile development and a DevOps culture to autonomous development.
Today, systems are event-driven, and feedback occurs in hours, even minutes. Out here, the ability to move forward is actually decided by humans (though we’ll soon release that responsibility to AI/autonomous systems). And, in this reality, code is no longer protected — rather, it’s the tool used to coordinate people and power up great products.
But the future of software development rests in a shift toward the autonomous, a context in which machines connect systems, feedback is instant, and automation goes as deep as the data does.
And the arrival path to this Promised Land is paved with first increasing engineer efficiencies with data, freeing up human engineers to focus on what they do best — the work — in a more aligned, optimized, and accurate way.
Simply put, data-driven Agile is a three-word way of describing the very real need engineering or DevOps teams (within a CI/CD lifecycle, powered by Agile processes like sprint planning) have to become more streamlined over time.
In short, these teams have an increasing need to measure and improve their performance with the power of real-time, objective metrics and reports. The data should (and does) come from Git repositories, and organizing this data gives teams insights into “where to cut the gravy train,” so to speak.
Unlike Waterfall’s fall (pun intended) and the eventual adoption of Agile methodology, data-driven Agile is more than just agile. In fact, it adds a layer of quality control and measurement to the processes of an Agile development team, rather than entirely supplanting the approach.
And that’s how you should think about the benefits it brings.
See, if you’ve been reading the tea leaves over the developer-led landscape in the past decade, you already know that the moment of Agile’s own evolution was inevitable.
It’s not simply because Agile, as a philosophy, drives toward progressive iteration — a concept widely embraced in everything from software development to human development (think, James Clear’s 1% improvement for building habits).
It’s also not simply because the United States Senate passed a bill that essentially labels technology and software as critical components of public infrastructure.
And, it’s certainly not only because we’re doing away with what Harvard identified as the “Highest Paid People’s Opinions” — also known as HiPPOs — for decision-making and, instead, allowing data-driven decision-making to lead the way.
An example of this is Tata Health’s method of collecting data about its engineering teams’ output, using Waydev’s Work Log report. By eliminating self-reporting, software engineering managers could gain granular visibility and truly objective data.
They then used this data to optimize the decision-making process and help them identify growth opportunities for their team members.
All of the above shifts are pieces of the puzzle, certainly. But, together, they still don’t entirely complete the picture.
The fact is that our move toward a data-driven approach must hit Agile and transform it because there’s a very real problem to be solved:
Now more than ever, engineering teams and the development lifecycle need insight and intelligence to support sustainable development, autonomous teams, and aligned business decisions.
For example, one of (old) Agile’s key principles was “Simplicity is essential.” That means, where possible, maximize the amount of work not done (because it didn’t have to be done). The “new,” data-driven Agile agrees with simplicity, keeps it intact, but adds a layer:
“Optimize the work in progress.”
Doing so is absolutely crucial because it allows engineering leaders to spot and eliminate places where the development lifecycle is getting bogged down.
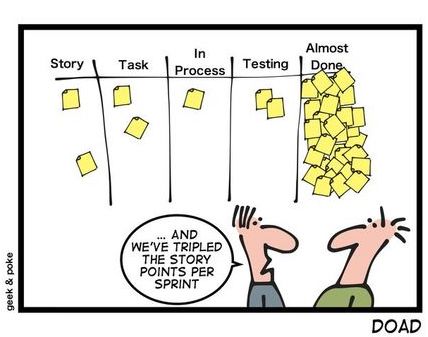
Essentially, what has become clear as we shift into this “new,” more agile Agile is that there’s a clear line in the sand: the “old” Agile processes worked when Agile was the new kid on the block and developer-led tools, platforms, and techniques were an exception.
But the global demand for digital services, though ever-increasing, has been here for over a decade. So we’re now in an age where there’s an increased and real need for anything that can improve the velocity of software development while reducing the risk of burnout.
And that’s where data-driven engineering leadership can transform everything from how managers communicate and offer feedback (through one-to-ones, supported by individual data and reports) to how frequently software is deployed (i.e., with a steady cadence).
Waydev’s data-driven Agile method delivers three significant whammies:
Show, not tell — that’s what data-driven engineering management empowers and that’s what Waydev’s functionality focuses on.
So, let’s take a look at an engineering KPI measured by the platform: Impact.
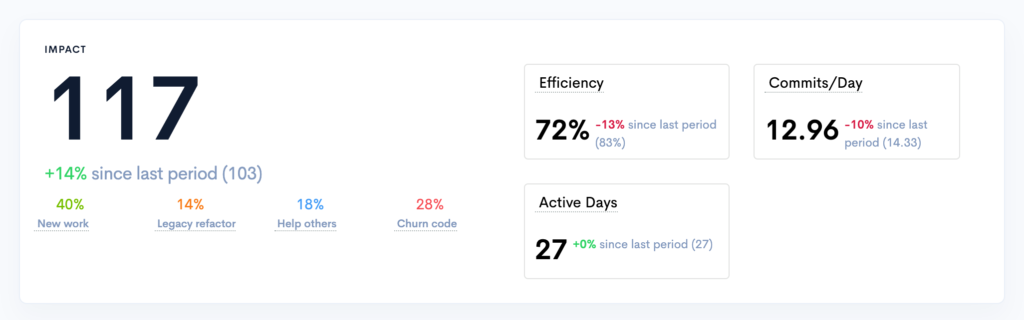
One aspect of developer or engineer productivity is to look beyond the lines of code when measuring code activity. “Impact” gives engineering management a clear way to do that. As a metric we came up with, it includes multiple data points such as:
So, the end result of this type of data is pretty powerful because not only does it amplify the magnitude of code changes, but it also ultimately gets engineering teams to take a critical stance on their own processes when reviewing that data.
Ideally, the intelligence and insights from data-driven Agile can help engineering leadership create a new baseline for development metrics. In the short term, what it can tangibly improve is software delivery and code accuracy.
Being a product-first software company with product-led growth is precisely the way it should be — this is one of the most significant transformations of a developer-led landscape in the past decade and a half.
However, product-led growth is only as good as the processes that support it and the engineers who build it.
The sophistication of the developer-led software market has also increased the pace of software development. Teams need to code faster, deliver features more quickly, and constantly update or modify their code while gaining clear insight about the nature of the changes.
The result is that changes can become opaque. It’s almost impossible to, for example, check to see if all code areas have been tested. It’s highly plausible, and even likely, that this lack of visibility then means risking the release of buggy, sub-optimal software.
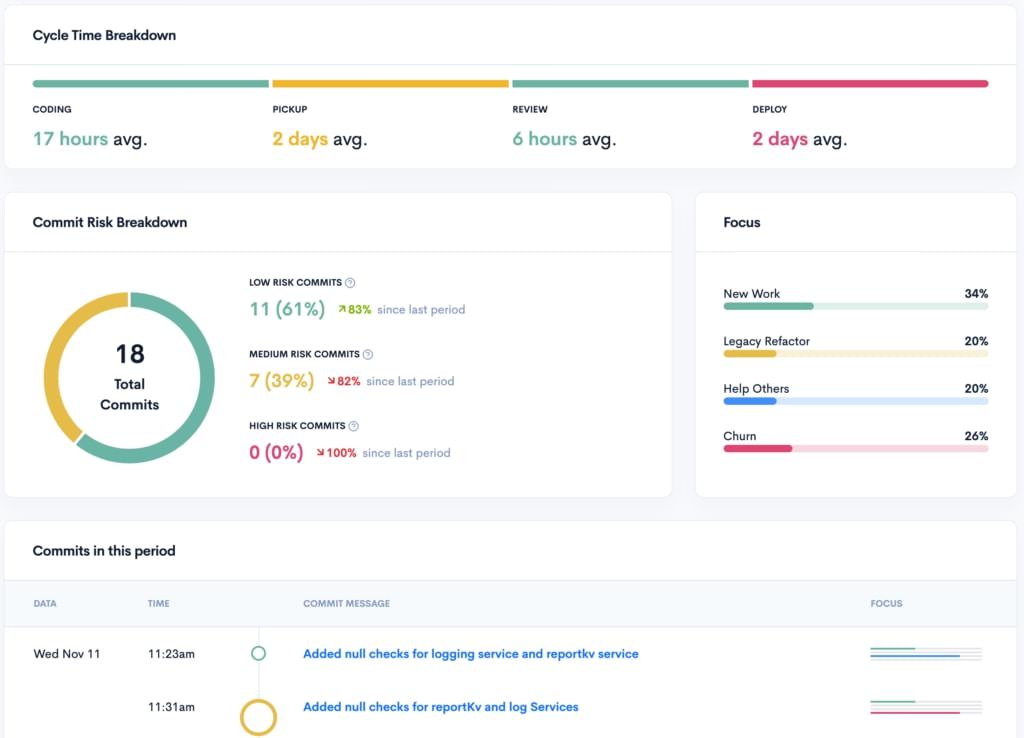
Instead, features like Project Timeline are essential to gaining deeper insight and visibility into the signals of notorious process blockers. With an emphasis on the following metrics, teams can gain clarity about how to evaluate performance:
…and more.
Let’s take a look at this situation:
If you’re not only aiming toward but actually implementing an environment that is dedicated to increasing software production velocity, you’ll likely experience two specific instances:
And this begs the question: can you accelerate velocity as an end goal while still maintaining transparency?
The answer is, of course, that you can — with the right tools.
The key lies in the processes, the details of data-driven decisions. Implementing a data-driven Agile approach means you’re also opening the door to a data-driven Scrum framework. On the surface, it seems as though “extra” data complexifies things like sprint planning and execution.
But, the right data about performance and productivity, coupled with real-time, objective reporting, actually helps to eliminate the ambiguities in the development process. You’ll still be able to maintain smaller iterations, conduct daily Scrum meetings, and participate in sprint reviews.
But adding data to back these up means you can eliminate some of the real issues with Scrum and Kanban. Instead, you’ll have a framework that allows teams to “follow the data” to the highest priority tasks (and effectively reprioritize tasks where necessary).
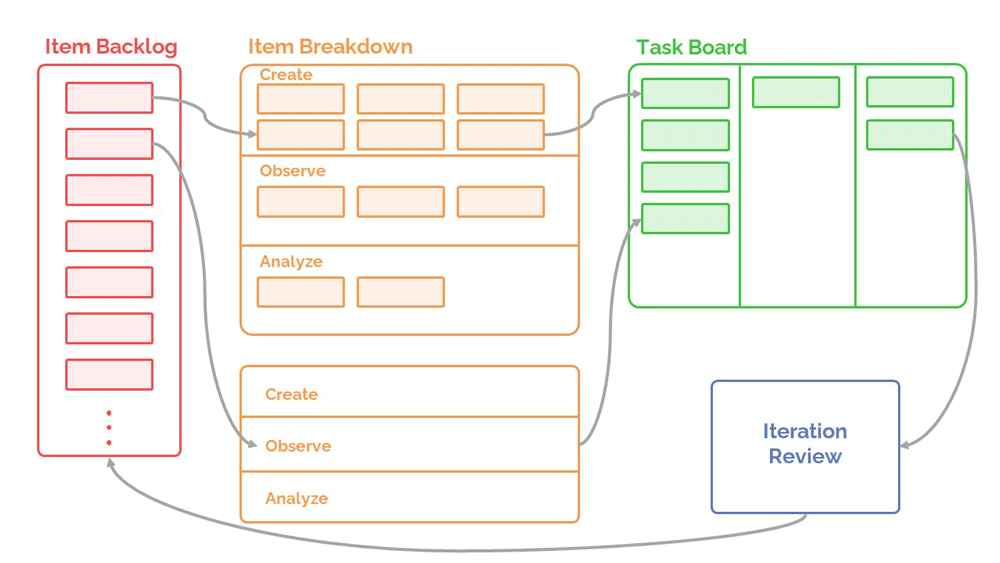
If it’s necessary, for example, to implement an iteration that lasts a day rather than three weeks (and vice versa), the data justifies that flexibility.
You need not stick to Scrum’s fixed-length sprints. Data Driven Scrum also resolves the issue of inherently unreliable task estimation because you have real data to back up precisely how much time tasks take.
These are the granular details that significantly improve a development team’s process. This gushes up for the ultimate alignment between a production team’s outcomes and business priorities.
In other words, why we’re doing the work and how we’re doing the work are in harmony when data is around.
One major takeaway that should be really clear is how software development analytics starts off by increasing engineering efficiency — i.e., improvements to process — but what it really supports is better team and peer-to-peer collaboration.
Waydev’s development analytics platform essentially paves the way for autonomous software engineering teams because there’s first a culture of autonomy. In other words, before software development can become autonomous, we need teams to be autonomous. And teams can do that when they have reliable, specific data to back up their decisions and actions
We can also wow your development team with data they never knew they needed — or could benefit from — when you schedule a demo with Waydev today.
Ready to unlock your SDLC productivity?












