Traditionally, engineering has relied on narrative, and subjective metrics like story points and tickets cleared to demonstrate business value.
Waydev provides engineering leaders with software development metrics in context to ask better questions and advocate for the team with relevant data:
How much of your team’s burn is going to refactoring old code?
What did everyone deliver yesterday?
How do Monday all-hands meetings affect productivity?
What were the 2 riskiest commits yesterday that could probably use a second set of eyes?
Waydev increase visibility about team contributions, see where the most significant impact is being made, identify areas to give concrete feedback, and help teams understand how process changes impact the team’s effectiveness.
Impact is a way to measure the ‘bigness’ of code changes that are happening, in a way that goes beyond simplistic measurements like LoC.

Impact attempts to answer the question: “Roughly how much cognitive load did the engineer carry when implementing these changes?”
Impact is a measure of work size that takes this into account. Impact takes the following into account:
The amount of code in the change
What percentage of the work is edits to old code
The surface area of the change (think ‘number of edit locations’)
The number of files affected
The severity of changes when old code is modified
How this change compares to others from the project history

One engineer makes a contribution of 100 new lines of code to a single file.
Compare that to another engineer’s contribution, which touches three files, at multiple insertion points, where they add 16 lines, while removing 24 lines.
The significance of each contribution can’t be boiled down to just the amount of code being checked in. Even without knowing specifics, it’s likely that the second set of changes were more difficult to implement, given that they involved several spot-edits to old code.
On the left we have someone adding 100 lines of new code to a single file. On the right is an example that represents only 24 lines of new code written, but there’s a bit more going on here:
this change required modifying previous work
the edits happened in 4 different locations
3 different files were affected
Even without knowing the severity of changes or comparing to historical changes, it’s probably safe to assume that the second contribution was more ‘expensive,’ and therefore carries is higher impact score.
Although change set #1 is technically more code, the added complexity of the work happening in change #2 could arguably make that change set at least as much work, and possibly more — even in the simplistic representation above, it’s clear that there’s more than just lines of code at play.
On large teams, it can be very difficult to see who is succeeding and who is struggling, or how the team as a whole is doing. Setting a standard around checking in code every day is a simple yet powerful target, acting as a Getting Things Done-esque tactic for larger engineering teams, to help ensure the ball moves forward every day.
Waydev proposes the idea of Active Days — any day where an engineer contributed code to the project. There are many different forms of engineering work: writing code, reviewing others’ work, discussing specs and architecture. Arguably the most important of these is contributing code, and it’s important for teams to make sure that time dedicated to things other than this stays at a reasonable level.
This is where keeping an eye on Active Days is valuable. Do you know how many engineering days your team loses each week to meetings, planning, or other non-engineering tasks? If your team is like most, you’re losing at least one day per week.
Let’s take a look at how this can be used:
Mark’s team has been asked to bring a third-party service in-house for financial reasons. The team has historically been a coding powerhouse and is generally thought to be one of the most productive engineering teams in the company.
Lately, however, something seems off: the engineers are grouchy and throughput seems a bit lower than normal. Looking at the team’s Active Days trend, Mark can see that this number has been slowly trending down over the last 12 weeks. The need for engineers to serve as de-facto product owners is causing a real, quantifiable drop off in their ability to check in code.
Knowing this, Mark can jump in and run interference for the engineers who are affected the most (e.g. those whose Active Days have fallen off hardest), and she is able to course-correct by bringing the team’s focus back to what they do best: writing great software.
What is the industry standard?
The global average of “days on deck with code” is about 3.2 days per week.
Subtleties of what’s right for each team can vary a bit. Developers who are working on ops stuff or non-code work might only have 1 or 2 Active Days.
Code churn is when an engineer rewrites their own code in a short period of time.
Think of it as writing a postcard and then tearing it up and writing it again, and then again. Yes, you technically wrote three postcards, but in the end, only one was shipped so we’re really talking about one postcard worth of ‘accomplishment’ from all that effort.
The same is true with code.
Let’s look a specific example and see at how churn impacts productivity:
Mark checked in the following javascript code on Monday:
On Tuesday, he decided to tweak his code and checked in this change:
Notice that the last line changed. So Mark churned one line of code. Or to put it another way, he gets no credit for the line of code he wrote yesterday.
On Wednesday he decided to tweak it again and checked the following code in:
Now he’s changed the last two lines of code. Again, Mark gets no credit for yesterday’s change and he loses credit for the original line of code he checked in on Monday. In effect, Mark has churned 100% of his code this week.
Simply put, Mark’s contribution on Monday and Tuesday was… nothing. He may be working hard but he’s not creating value for those efforts.
In our simple example, the net result was that Mark took three days to get this feature right. Now in all fairness, this may or may not be his fault. It could be the product manager wasn’t clear. It could be the spec changed. It could be he got the requirements wrong.
In any case, as Mark’s manager, you need to look a little deeper as to why he keeps rewriting the same lines of code over and over again. If you’re on the lookout for spikes in churn, you can diagnose problems early and keep your team from getting discouraged.
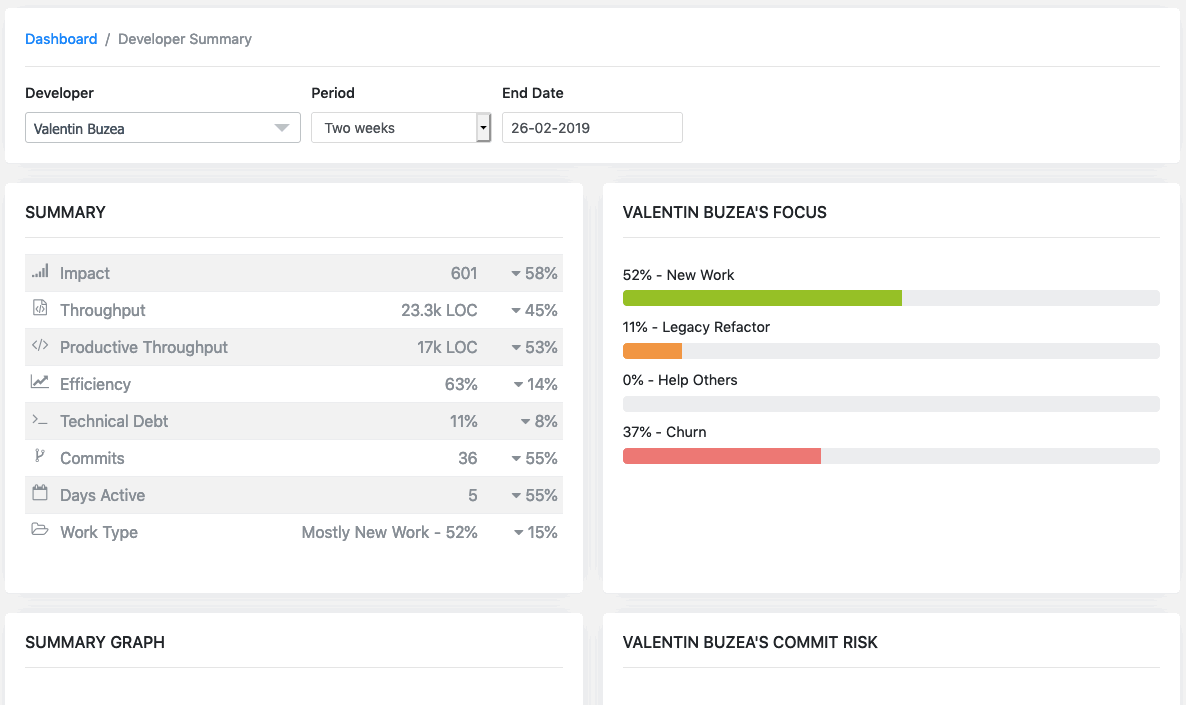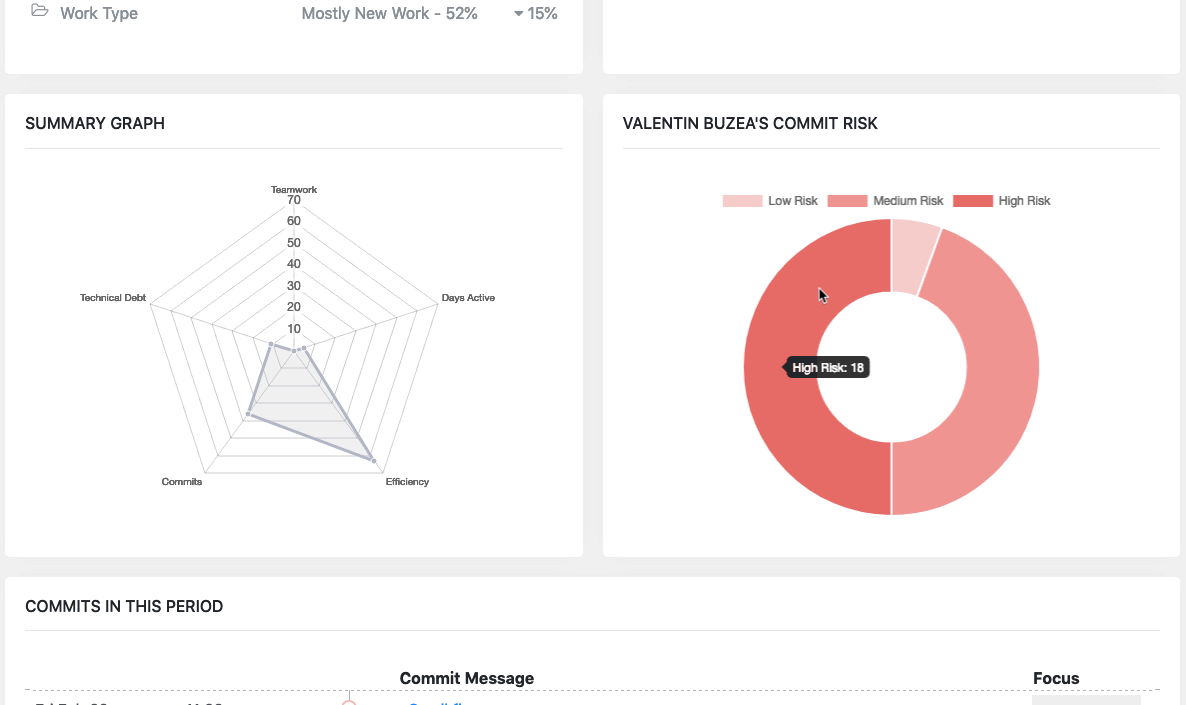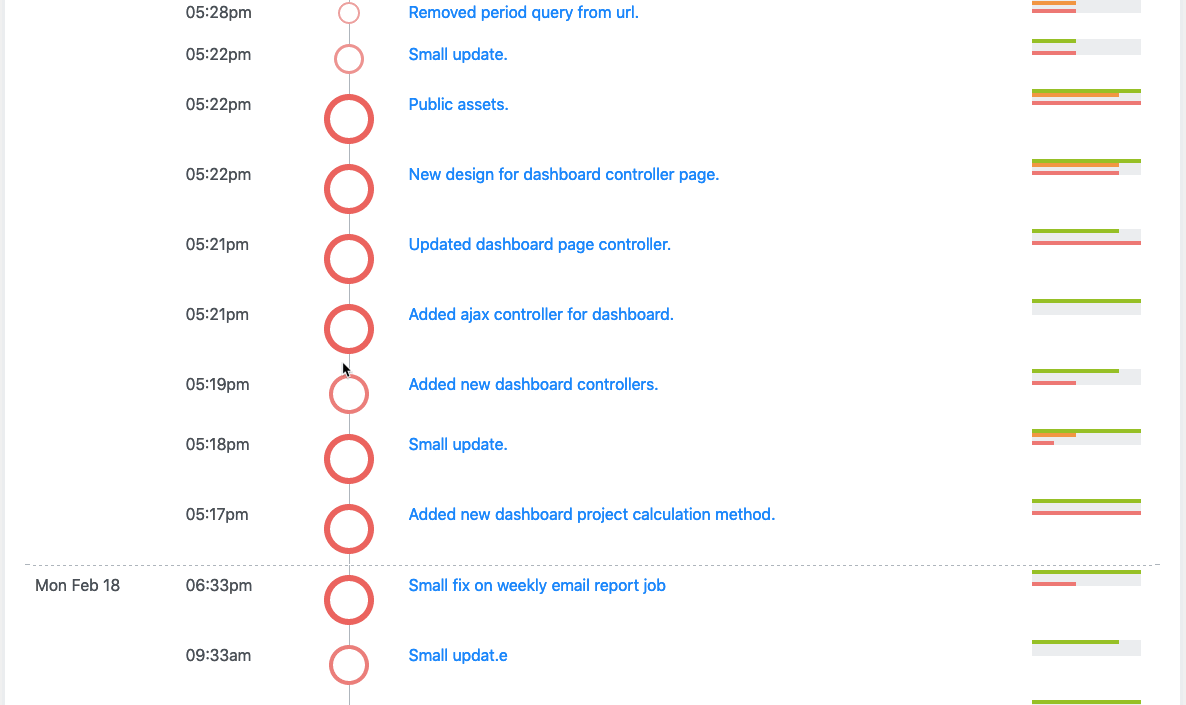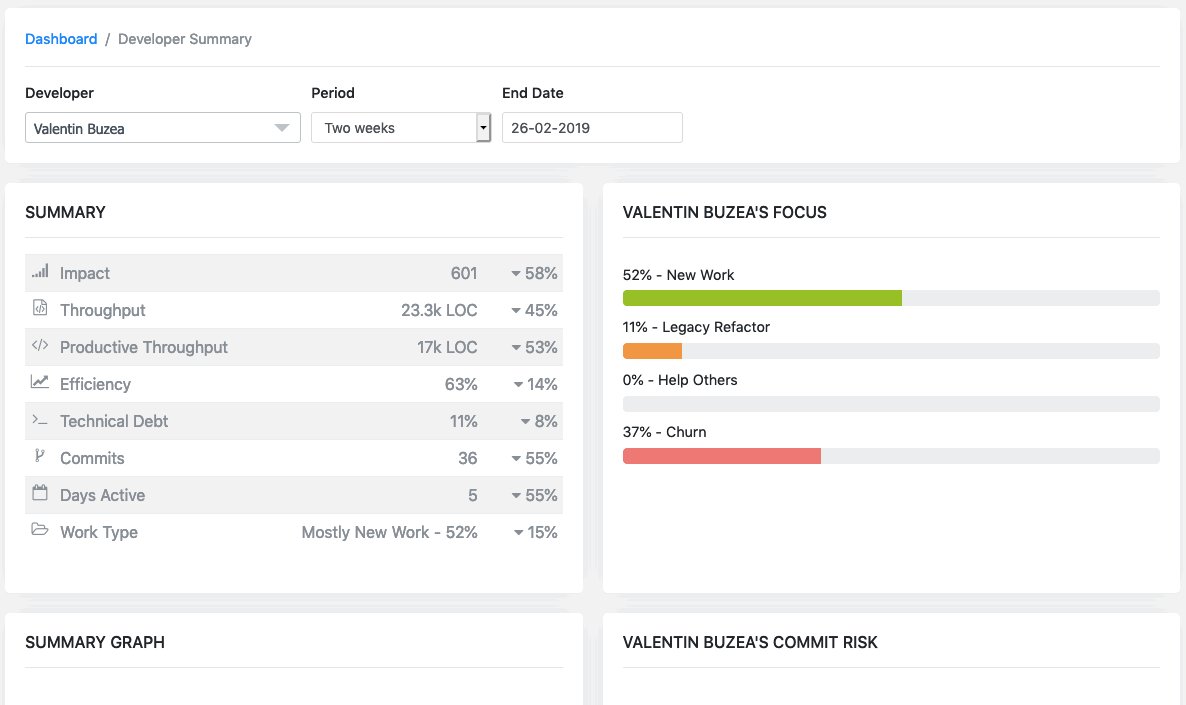
Waydev helps you see the different types of work:
New Work—Brand new code that does not replace other code.
Legacy Refactor—Code that updates or edits old code.
Help Others—where a developer modifies someone else’s recent work (less than 3 weeks old)
Churn—Code that is rewritten or deleted shortly after being written (less than 3 weeks old)
New work
New work is a measure of how much fresh, blue sky work is happening over time. The amount of attention to new work depends entirely on the phase of the product and business. It is very normal for a growing company to aim for more than 50% of their work to be “New Work” which is indicative of forward progress.
Legacy Refactor
Legacy Refactor is the process of paying down on “technical debt”—is traditionally very difficult to see. New feature development oftentimes implies re-working old code, so these activities are not as clear cut as they might seem in Scrum meetings. As codebases age, some percentage of developer attention is required to maintain the code and keep things current.
The challenge is that team leads need to properly balance this kind of work with creating new features: it’s bad to have high technical debt, but it’s even worse to have a stagnant product. This balancing act is not something that should be done in the dark, particularly when it’s vital to the success of the whole company.
Objectively tracking the percentage of time engineers spend on new features vs. application maintenance helps maintain a proper balance of forwarding progress with long-term codebase stability.
Help Others
Help Others describes how much an engineer is replacing another engineer’s recent code—less than 3 weeks old.
Churn
Churn is when a developer re-writes their own code shortly after it has been checked in—less than 3 weeks old. A certain amount of Churn should be expected from every developer.
For example, a Churn rate of 9-14% for a senior engineer might be completely expected. Unusual spikes in Churn can be an indicator that an engineer is stuck. Or high Churn may also be an indication of another problem like inadequate specs. Knowing immediately as your team is experienced churn spikes helps you have timely conversations to surface any potential problems.
Risk is a measure of how likely it is a particular commit will cause problems. Think of this as a pattern-matching engine, where Waydev is looking for anomalies that might cause problems.
.gif?alt=media&token=9a13ed4a-4ac1-489d-9592-4249c4742e26)
Here are some of the questions we ask when looking at risk:
How big is this commit? Are the changes tightly grouped or spread throughout the codebase? How serious are the edits being made — are they trivial edits or deeper, more severe changes to existing code?

Risk helps teams put their attention where it’s most needed. This not only helps with quality control, but serves an incredible tool for building engineering talent: by concentrating review on outlier commits, engineers receive high-quality feedback and suggestions for improvement where it’s needed most.
Impact — It is a way to measure the ‘bigness’ of code changes that are happening, in a way that goes beyond simplistic measurements like lines of code.
Throughput — Total amount of code of new, churn, help others and refactored code.
Productive Throughput — The proportion of code without churn.
Efficiency — Is the percentage of an engineer’s contributed code that’s productive, which generally involves balancing coding output against the code’s longevity. Efficiency is independent of the amount of code written.The higher the efficiency rate, the longer that code is providing business value. A high churn rate reduces it.
Technical Debt— Is the amount of refactoring code done by the developer.
Commits — The amount of commits done by the developer.
Days Active — The amount of days the the developer check in code.
Work Type — The highest types of work an engineer is focused on.
Risk is a measure of how likely it is a particular commit will cause problems. Think of this as a pattern-matching engine, where Waydev is looking for anomalies that might cause problems.
Here are some of the questions we ask when looking at risk:
How big is this commit? Are the changes tightly grouped or spread throughout the codebase? How serious are the edits being made — are they trivial edits or deeper, more severe changes to existing code?
Risk helps teams put their attention where it’s most needed. This not only helps with quality control, but serves an incredible tool for building engineering talent: by concentrating review on outlier commits, engineers receive high-quality feedback and suggestions for improvement where it’s needed most.
Submitter Metrics quantify how submitters are responding to comments, engaging in discussion, and incorporating suggestions. Submitter metrics are:
Reviewer Metrics provide a gauge for whether reviewers are providing thoughtful, timely feedback. Reviewer metrics are:
Comment metrics are:
Sharing Index metrics are:
There are six metrics that comprise the PR Resolution report:
If you want to find out more about how Waydev can help you, schedule a demo.

Ready to improve your SDLC performance?










Waydev analyze your codebase from Github, Gitlab & Bitbucket to help you bring out the best in your engineers work.