
Estimated reading time: 12 minutes
In an ever changing tech industry with many breakthroughs and emerging trends, performance remains a very important topic. While there are many layers involved in developing innovative software technologies, the basics, such as engineering teams efficiency and productivity, remain a key aspect. Understanding what it takes to have high performing teams and how to measure this performance is something that many industry researchers have struggled to define. The four DORA Metrics are an industry staple for assessing development team performance – Deployment Frequency (DF), Lead Time for Changes (LTTC), Change Failure Rate (CFR), Mean Time to Recovery (MTTR).
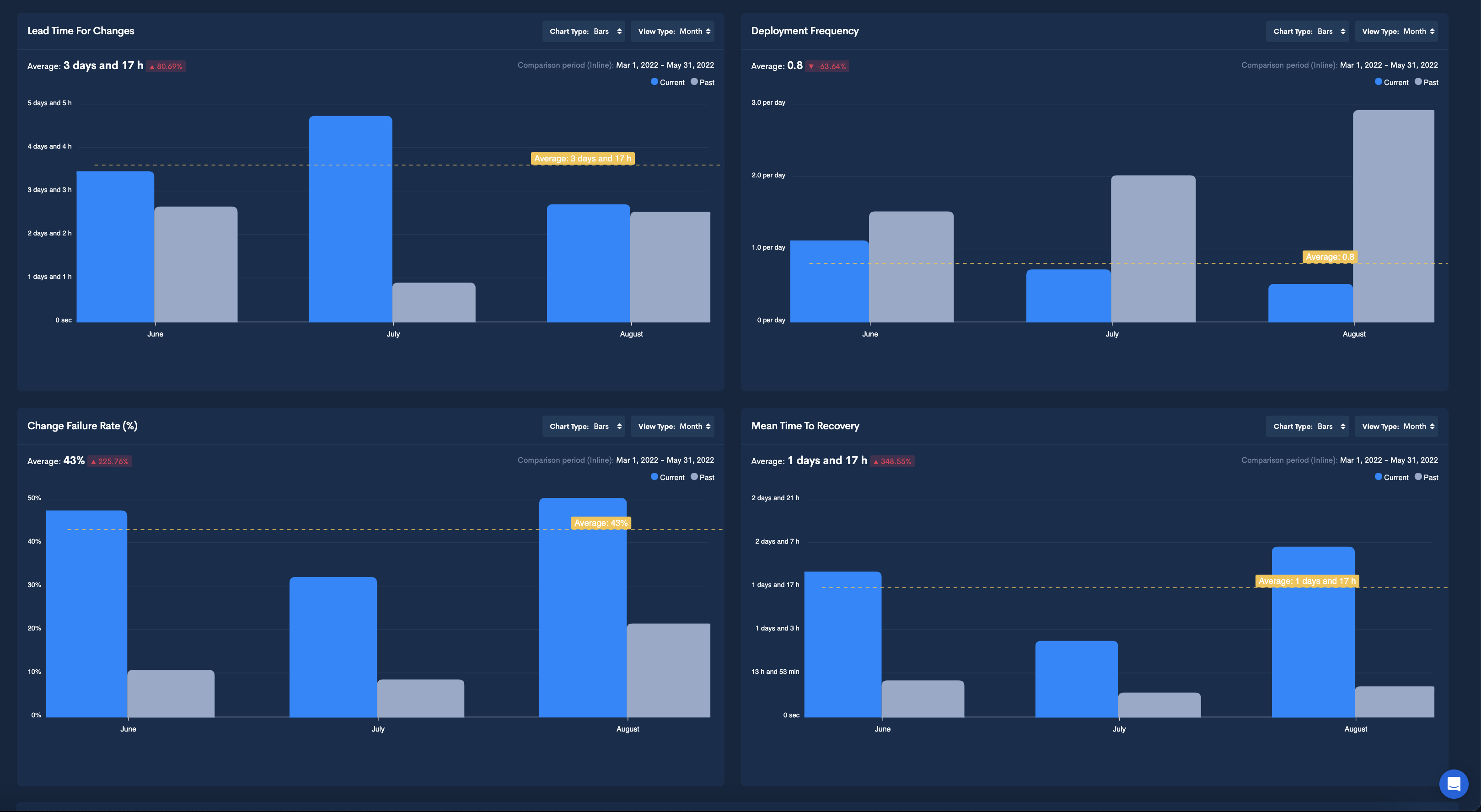
Among these four DORA Metrics, Mean Time to Recovery is an important indicator of your engineering teams’ response time when issues appear. MTTR measures how long it takes to repair a system in downtime and the average time it takes to restore it to functionality. Keeping track of this metric is essential for assessing a system’s reliability, your devops performance, and customer satisfaction (a valuable measurement, in the newer custom-centric software development frameworks).
Waydev’s DORA Metric all-in-one dashboard can give you valuable insight into this important metric. By keeping track of Mean Time to Recovery you can make data-driven decisions regarding your processes, and encourage an environment of continuous improvement.
The DORA Metrics concept emerged from the need to better define and understand what performance means in a software development environment. It allows tech leaders to compare their engineering teams’ performance with industry averages, giving you insight into possible issues, sources of bottlenecks, and especially opportunity for growth and improvement.
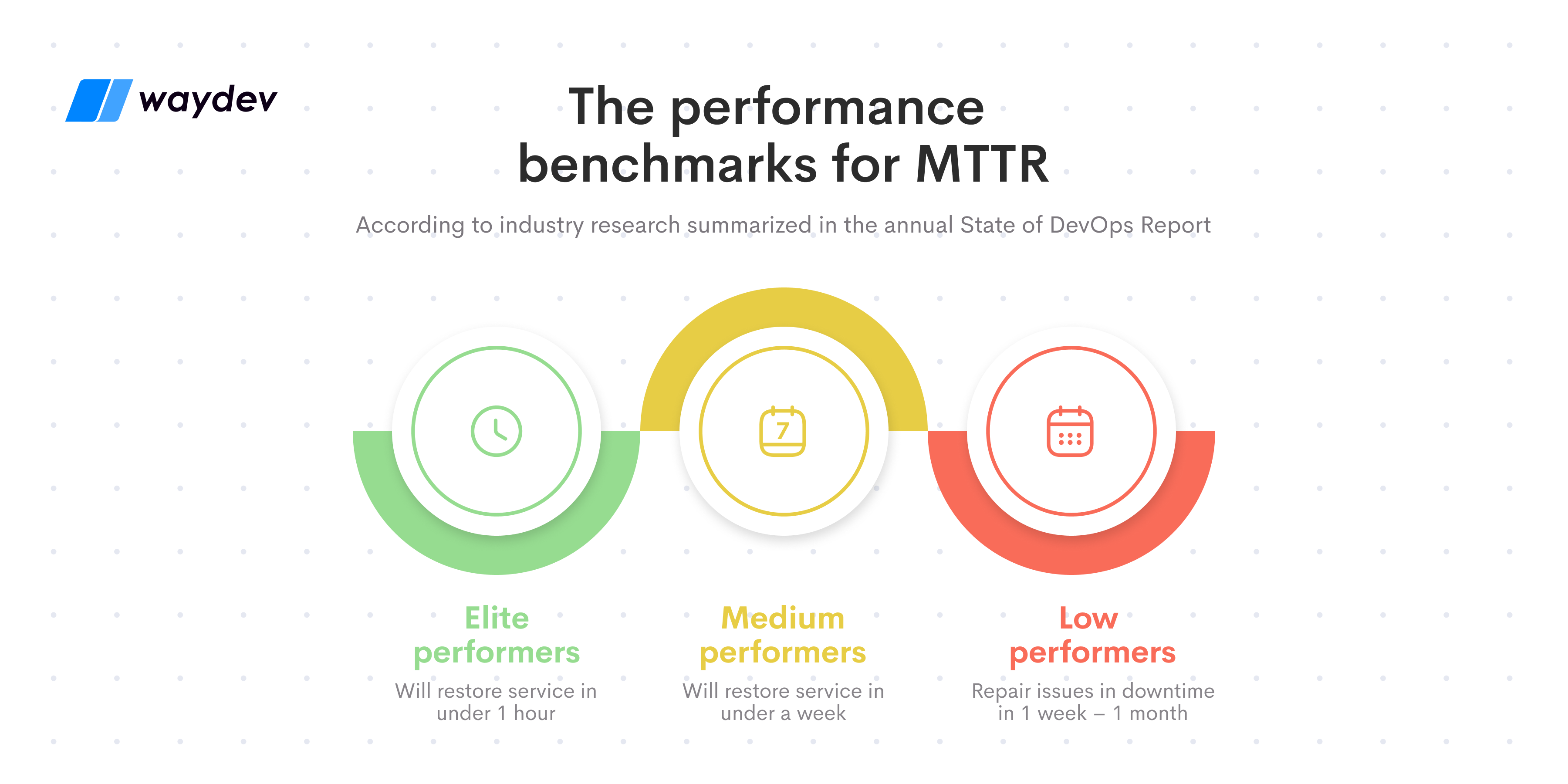
Mean Time to Recovery is one of the four DORA Metrics and a great way to evaluate your engineering teams’ response time when issues appear – of course, the quicker the response, the better performing the team is. According to industry research summarized in the annual State of DevOps Report, elite performers will restore service in under 1 hour, while medium ones in under a week, and low performing teams repair issues in downtime in 1 week – 1 month.
MTTR is considered a reliability or stability metric, because it tells you how resilient your system is and how fast it can be restored to functionality when failures appear. How high or low your MTTR is also shows the financial impact of downtime on your business. MTTR is also a performance metric, as it provides insight into your teams’ ability to restore the service.
There are many reasons why constantly assessing Mean Time to Recovery is essential for your organization, ranging from internal performance to end-user satisfaction. This practice provides valuable insight into your day-to-day practices, such as incident management, engineering teams’ performance, and helps you evaluate customer satisfaction. Analyzing these complex matters will facilitate identifying issues and delays to your delivery and maintenance practices, and they will help you make informed decisions to continuous improvement.
MTTR is an important metric in determining the system’s reliability and recovery time when issues appear. To get the maximum benefits in collecting data about your Mean Time to Recovery, you need to understand how to properly calculate and interpret this metric.
MTTR = Total Downtime / Number of Incidents

Here is a breakdown of this formula:
A few software development metrics relate to downtime and system failures, and many of them are used interchangeably. While they define similar concepts, there are some differences between them. Mean Time to Repair is often used as a substitute for Mean Time to Recovery, and while the two are related to fixing downtime, they describe different stages of the process.
Mean Time to Repair is a performance metric that speaks to the stability of your system. But this metric only refers to the time spent on the actual fixing of the issues. The specific repair activities such as diagnosis, replacing defect components, repairing, adapting, and testing.
Mean Time to Recovery includes more than the fixing stage – it shows the entire process of diagnosing and restoring a system to proven functionality. This means this metric is defined as the average time spent to detect the issue, do the necessary process to fix it, test the system and verify that it works over time.
Mean Time to Recovery is an important metric and measuring it over time can provide valuable insight into your processes and vulnerable areas. Why downtime occurs, your teams’ response time, and incident management practices within your organization can give you the opportunity for business growth and less wasted resources.
Here is a guideline to the most important benefits of tracking and continuously improving Mean Time to Recovery:
Measuring MTTR means understanding why your system fails, where recurring issues appear, and your vulnerable areas. Tracking this metric over time can show patterns of disruption and this can provide valuable insight into why downtime occurs. Having this important data can provide the opportunity for improvement and less downtime.
The more often the system is down and the more it takes to restore it to full functionality, the more dissatisfied your customers will be. Keeping a low MTTR will enhance customer satisfaction immensely and keep your organization on top in a very competitive market. Keeping track of MTTR and continuously improving it provides great results in the long run.

Keeping a low MTTR will boost team members’ motivation and this will ultimately show in their productivity and efficiency. There are many ways to improve productivity, and one of them is by wasting less time on fixing issues. A more stable system with less downtime means there’s more time for engineers to concentrate on new workpieces and finding innovative solutions. By measuring your MTTR and understanding where recurring issues arise, you can create a more productive work environment.
Improving operational efficiency is another benefit that comes with measuring and optimizing your Mean Time to Recovery. Keeping track of MTTR improves your everyday processes and operations because it allows you to identify problem sources for failures, boost (APM) application performance monitoring and issues detection, and streamline your incident management processes. So measuring incident metrics is not just about identifying problem areas, but also understanding how efficient you and your teams are in detecting and solving them. This gives you the opportunity to improve operational efficiency by choosing techniques such as improving collaboration and transparency, implementing automation, and optimizing workflows.
Monitoring MTTR has an impact over your company’s financial and operational performance. Continuous improvement of this metric enhances system availability by tracking root problems and improving incident response. Recurring issues can reveal infrastructure vulnerabilities and greater risk areas – this is where great risk management comes into play to mitigate these risks. Tracking and optimizing MTTR strengthens your business resilience over time by identifying problem areas and implementing strategies to better manage them.
Keeping track of failure or incident metrics provides a great tool for your decision making. Understanding why systems fail, how often, and what is your teams’ response time can give you context and reveal recurring patterns. This means you have an opportunity to identify and improve those problem areas, and reduce incident occurrence.
Waydev is an engineering intelligence platform that integrates the engineering toolstack with an all-in-one unified DORA metrics dashboard to bring you comprehensive data about your teams’ performance and incident response time. Waydev integrates these measurements with other tool-specific metrics, such as Cycle Time, to gain visibility into the entire delivery process and how it’s impacted by performance.
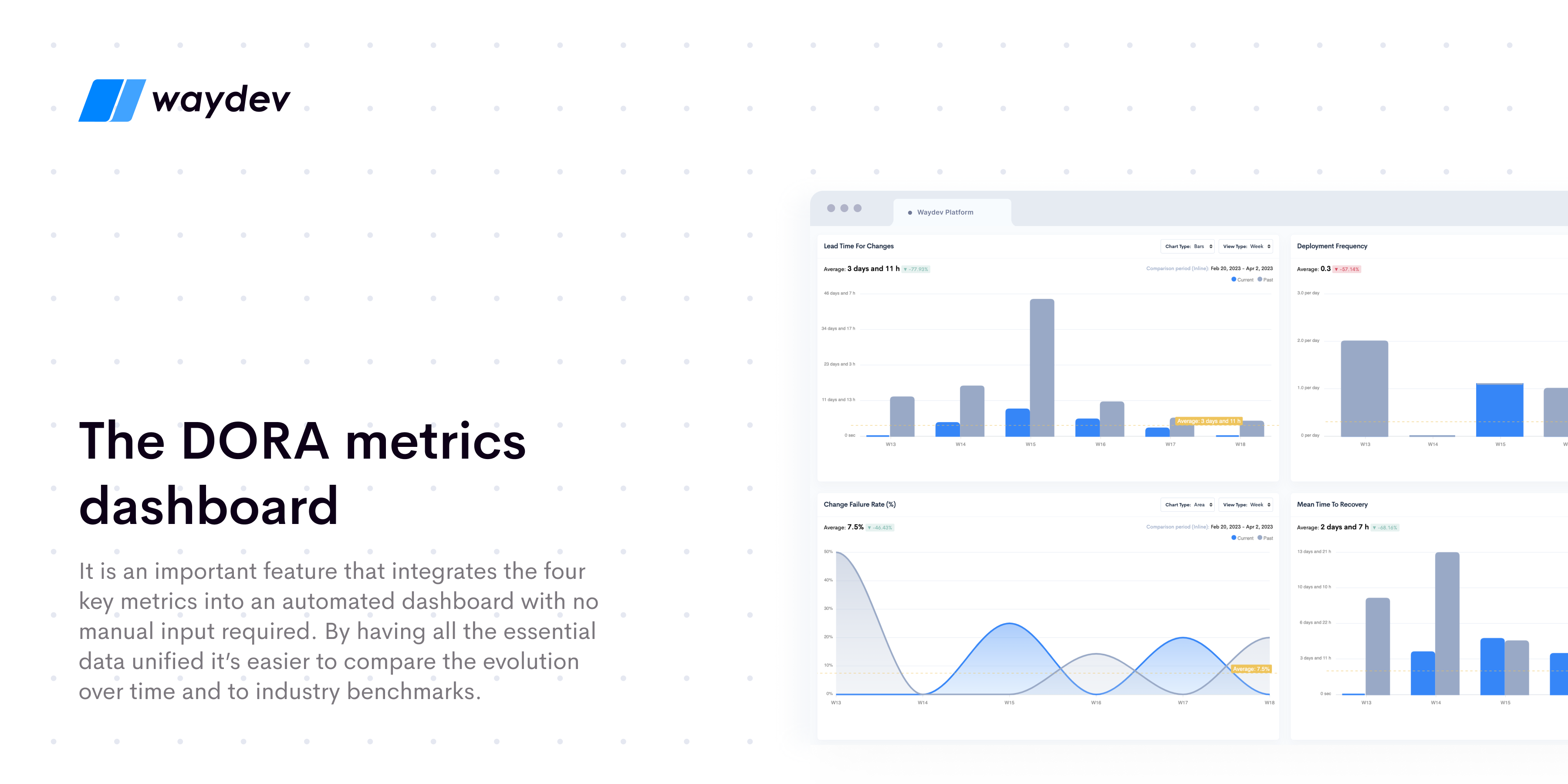
The DORA metrics dashboard is an important feature that integrates the four key metrics into an automated dashboard with no manual input required. By having all the essential data unified it’s easier to compare the evolution over time and to industry benchmarks. This can provide valuable insight into vulnerable areas and improvement opportunities, by aggregating data from multiple sources, measuring and centralizing measurements, and continuously improving it. Our platform also allows you to dive deeper into why failures occur with root cause analysis and identify certain areas that tend to fail more often.
The DORA Metrics concept was truly revolutionary for how you look at software development performance through the quality, velocity, and stability of our system solutions. But industry professionals believe that understanding what drives the success of your teams and your delivery processes goes way beyond the four DORA Metrics.
According to Nathen Harvey, developer advocate at Google Cloud that focuses on optimizing and helping organizations implement the DORA model, thinking only these four metrics are the key to all your problems is a pitfall: <I see a lot of teams that say – “The way we’re going to get better is by looking at these four measures.” Truly embracing the findings of DORA requires going beyond those four keys.> Nathen Harvey also points out that you need other tools with their own metrics to integrate with your DORA metrics in order to get the full story of how performance affects your delivery processes and business goals. In his own words – <Having tools like Waydev, where we can take a bigger picture and look at more data, helps provide a more comprehensive view of how a team is doing.>

Implementing the DORA metrics within your organization is not just about those four key metrics, but also putting them in a larger context of other measurements. But more importantly, it’s about harboring an environment of continuous improvement by analyzing the collected data and adopting optimization strategies. The developer advocate says that the best way to use these indicators is to identify bottlenecks and teams’ capabilities, implement changes accordingly and watch numbers change.
Whether your MTTR is high or low, it’s important to adopt long-term strategies for continuous improvement of this metric. Implementing optimization practices will help with better allocation of resources, less downtime, and to perfect your incident management skills. Here are a few improvement strategies for lowering your Mean Time to Recovery:
Waydev is a complex engineering intelligence platform that can help your efforts of optimizing software engineering processes. According to Waydev’s co-funder, Alex Circei – <Back in 2017, we started with the code level metrics; then we moved to PRs, then we added tickets, then DevOps metrics, then DORA Metrics. Now, I think we are capturing the whole spectrum of development.> By integrating DORA Metrics with the platform, Waydev provides a comprehensive view on your delivery processes, teams’ performance and how this impacts your business goals at a financial and operational level.
Measuring Mean Time to Recovery provides valuable insight about your system’s stability and reliability, and also about your recovery process and incident response. It is a complex reliability and performance metric that can be used to improve problem areas that cause recurring incidents. Monitoring and optimizing your MTTR can have a massive impact over your resource allocation, customer satisfaction, and overall business performance.
Platforms such as Waydev can prove invaluable for top executives that want to continuously improve their performance and streamline their delivery process. By integrating the DORA Metrics with other insightful engineering metrics, we can give you a birds-eye view of your entire operations and what needs improvement.
Contact us today to start exploring Waydev’s dashboards for better MTTR numbers and optimizing your incident management practices.
Ready to unlock your SDLC productivity?












